第一次看见注意力机制的时候看得我一懵一懵的,看不懂说什么;第二次看见注意力机制的时候看懂了一点,但完全不知道为什么几个矩阵就相乘了;第三次我和AI还有各种资料打滚了一番,终于有了我自己的理解。
李沐的D2L中将注意力机制与核回归一起讲,我觉得是个可取的思路,在本文中我也会参考这个思路,从头开始讲如何理解注意力计算公式。
简单的想法:带着目的思考
“注意”让信息更有价值。
摆在你面前有很多篇文章,如果你没有带着某个目的,那么对你来说,这些文章的价值应该是一样的。
但倘若你有很强的倾向性例如「我要看科技文章」,那么带着这个目的去评估文章的价值,科技文章的价值应该因为这个目的而获得加成,有着比其他文章更高的价值。
注意力机制便是类似这样一个根据不同目的(或者说注意)进行加权的算法。
核回归
注意力机制的超级老祖先。
不过在讨论注意力之前,我们可以先看看统计学的东西——核回归。
我们知道,回归是在对自变量x和因变量f(x)建模,一种简单的回归办法是算平均值:
不过显然这个方法过于”简单“,不能很好的预测真实值。
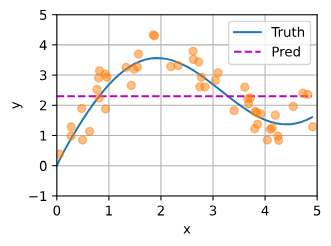
算平均值还是不够聪明,一种更好的方法是用一个关于实测的
这里不会去讨论
重点在于,核回归通过已有
参数呢?
我们可以注意到,这个核回归是不带参数的,核回归实际上也是可以变为带参数的形式,也就是
这样的形式,此处不做谈及,感兴趣可以看D2L。
注意力机制
讲完了简单的核回归,现在可以讲进一步的注意力机制了——其实就是矩阵化后的核回归。
先做一个最简单的注意力。前面的核回归并没有参数化,引入
问题:这个是我的学习笔记,评价笔记,检查错误,润色补充。
AI 补充
让AI补充一下,提示词见上面
修改历史
- 初稿。2025-06-26