也是来品读这本神作。
不会记住这本书的所有内容,更多的是对有思考理解的地方的记录。
WARNING
斜体字部分为个人吐槽,虽然正文里面我也在吐槽了。
前言
开头有很长的名言,可见这本书背后的人的背景——当然是 C++ 之父。很多眼熟的自媒体名人或者哪个教授委员会的人也在写推荐,给人一种群星璀璨的感觉。
很期待这本书了。甚至在网上看见有人说这本书是其他语言入门 C++ 的精华,或者说现代 C++ 的精华。
ps: 已读完,并写了书评,详见 文末
第1章 基础
ISO C++ 标准定义了两种实体:
- 核心语言特性
- 标准库组件
C++ 标准库可以由 C++ 自己来实现,只有在线程切换需要少量机器码。作者以此验证 C++ 的强大。吐槽,确实强大,但是很折磨。
函数
函数声明的时候写不写变量名都一样。
void print(int);
void print(int a);而且函数有类型重载。
这个没有名字的类型声明可能用处在匿名函数和函数参数上吧,没搞懂这个设计的目的是什么。
类型、变量
通常其他类型都是 char 的整数倍。
标准库有类型别名可以指定类型的尺寸,比如说 int32_t。我还是头一回知道。
变量初始化很有意思,可以使用花括号进行统一初始化(好像是C++11的特性)。我也没听说过这种新的初始化方式
double d1 = 2.3; // C 风格
double d2 {2.3}; // 初始化列表
double d3 = {2.3}; // 用 {} 初始化的时候 = 可以省略。
complex<double> z = 1; // 有隐式地初始化
complex<double> z2 {d1,d2};
complex<double> z2 = {d1,d2};
vector<int> v {1,2,3,4};用 = 初始化是 C 语言传统方式,如果拿不定用什么方式初始化,就用 {} 列表初始化,抛开其他因素不谈,{} 形式的初始化可以避免窄化类型转换(=会进行窄化类型转换是为了兼容 C 而产生的不幸的后果)。
int i1 = 7.8; // 不会报错
int i2 {7, 8}; // floating-point to integer conversion建议有合适的值在定义新的标识符名称,而不是提前定义。因为变量通常只有在有限的特定情况可以处于未初始化状态。
auto 自动推导类型,这个已经很有名了。
用 auto 的时候倾向于 = 初始化,因为没有隐式类型转换风险。不过喜欢一致性也可以用 {}。
我才知道原来C++的new是malloc那种到了堆内存上的,delete释放才消失,而不受作用域控制。其实很好理解,因为我第一次接触 C++ 的时候我还没搞懂内存模型。
常量
C++ 有两种不变性:
- const:意味着「我承诺不修改这个值」。其实和 C# 的那个 const 是一样的。
- constexpr:意味着「请在编译时计算出它的值」。这主要用于声明常量,编译器会把这个数据放在只读内存区域里面。constexpr 的值由编译器计算。
constexpr 用在函数上的话就是如果参数是常量,可以在编译时求值;否则退化到运行时。
consteval,其实要求也和 constexpr 差不多。不能有副作用,只能用输入参数作为信息,所以基本上是数学那种纯函数。这玩意和 inline 不一样,需要注意。
更正:constexpr是可能需要在编译时求值,constevel 是编译时必须求值
指针、数组和引用
才知道一种全新的视角,也就是把 * & 看成前置一元操作符,在此前我一直看成关键字相似的东西。
有一个不是很了解但是很熟悉的范围 for
int v[] = {0,1,2,3,4,5,6};
for (auto x : v) {
cout << x << '\n';
}
for (auto x : {10, 21, 32, 43}) {
cout << x << '\n';
}
for (auto& x : v) {
x += 1;
}需要注意的是传统的写法都是复制一份,所以如果要修改的话就用 & 操作符拿引用。
{10, 21, 32, 43} 原文没说,但是我查了一下是一个叫 initialized_list 的东西。特性类似无法更改其值的数组。
引用的好处是不用像指针那样每次都要 * 解引用。
标记空指针的办法是将指针取值为 nullptr,所有指针类型都共享同一个 nullptr
旧式代码中,经常用 0 或者 NULL 替代 nullptr,为了消除潜在歧义所以出现了 nullptr。
点名一款 undefined null none 能组合做神秘小运算的语言
检验
这个 if switch while 吧,看的习惯的还好,不习惯就难受了。
switch 的 case 需要常量表达式,这点已经是经典c就有的活了。
if 检验变量也能语句内定义了。还挺跟潮流
void do(vector<int>& v) {
if (auto n = v.size(); n!=0) {
// n!=0
}
//...
}变量值 !=0 判断还有 !=nullptr判断是常见的,所以可以省略。指针就用 != nullptr,变量会用 !=0
void do(vector<int>& v) {
if (auto n = v.size()) {
// n!=0
}
//...
}映射到硬件
其实这段主要在讲的事情很简单—— C++ 直接把机器的内存当作序列内存地址,并且直接将有类型的对象放入这些地址。
如果用过其他语言知道其他语言的内存特性就知道了,变量名代表的不一定是值本身,可能是引用。而在 C++ 这里,值就是值,引用就是引用。大概可以这么理解。
C++ 的内存方式和 C 是一致的,和 Java C#等其他语言不同。
初始化
初始化和赋值不同。赋值要成功,要求被赋值的对象必须拥有有效的值(地址);而初始化则是将没有被初始化的内存区域变成有效的对象。
int& r = x;
int& r2 {x};这里的 = 不是赋值,而是初始化(将 r 绑定到 x)
建议
有挺多建议的,不过全写肯定也记不住。
- 想要写出好的程序,你不必了解 C++ 的所有细节
- 请关注编程技术,而非语言特性。
- 把有意义的操作「打包」成函数,并给它起个好名字(我记得在这章哪里看到过,说如果抽出来的函数想不出名字,可能是程序和抽象的时候有问题)
- 一个函数最好只执行单一逻辑操作
- 保持函数简短
- 函数重载的适用情况:函数们的任务相同但参数类型不同。
- 如果函数不允许副作用就声明成 constexpr 或 consteval
第2章 用户自定义类型
内置类型特意设计偏低层,由此在高层设施构造中,需要通过 C++ 精致的抽象机制来进行编写。
结构体
纯数据,其他跟 C 差不多。不过也有 class 的特性
类
将数据表示形式和操作联系在一起。
一个固定尺寸的「句柄」指向位于别处的一组数量可变的数据上(比如说new分配的自由存储上)这是 C++ 处理可变数量信息的一项基本技术。C 不也是这么干的么,都一样的。
struct 和 class 一致感觉是历史包袱导致的,C++ 把 C 的历史包袱也接过来了。
枚举
enum class 和 enum 的区别是 enum class 更加严格,会判断相等时枚举类型,而 enum 单纯是值而已。
枚举值的作用于在他们的 enum class 内,所以在给 enum class 写方法的时候可以用 using enum xx 来把 xxx::a 简写成 a。
感觉枚举 enum class的class是为了兼容C而多此一举出来的语法。历史包袱还在发力。
Union
union 和 C 的 union 一样。
不记录类型,所以需要一个标志变量配合 union 用,不然很危险。也就是说不要单用 union。
union 也是 C 下来的包袱。
建议
- 用 class 表达接口与实现的区别。实现就是真正的底层内存 (基本类型),接口指的是用class的方法写就不容易搞乱底层内存.
- 优先用 enum class
- 别用裸 union,用 std::variant 很容易想到了
第3章 模块化
引言讲的思想核心是分离接口和实现。
这里的接口和实现并不是 OOP 那种以 class 为基本要素的接口和实现,而是说声明和定义的分离。
分离编译
C++支持一种名为分离编译的概念,用户代码只能看见所用类型和函数的声明。有两种方法实现它。
- ·头文件(3.2.1节):将声明放进独立的文件,该文件叫作头文件,然后将头文件以文本方式
#include到代码中你需要声明的地方。- 模块(3.2.2节):定义module文件,独立地编译它们,然后在需要时
import它们。在import对应module时,只有其中显式export的声明是可见的。
头文件是 C 时代就有的,模块则是 C++20出现的新特性。
讲得真好啊,突然能理解头文件的作用了。在调用方的时候需要以头文件当接口调用,在定义方的时候需要以头文件当接口对照实现。文件之间是独立的,编译的时候可以分别编译。这让我想到编译原理,不论是动态链接库还是静态链接库何尝不需要接口(头文件或者模块)来进行调用呢?
.cpp 和包含它 #include 的 .h 文件被叫作一个翻译单元。
#include 也是有缺点的。
- 编译时间:每次 include 都要预处理。
- 依赖顺序:头文件互相影响的话,include 顺序不同结果不同。
- 不协调:两个实现实现了同一个接口可能会撞车。
- 传染性:头文件为了完成声明,需要 include 其他头文件。
头文件自 1970 年代初期就整了一堆活,现在应该用模块。给老资历跪了
C++20中,我们终于拥有了语言级的方式来直接实现模块化。
难蚌。
export module Vector; // 定义一个 module,名为 Vector
export class Vector {
public:
Vector(int s);
double& operator[](int i);
int size();
private:
double* elem;
int sz;
} // 导出接口
Vector::Vector(int s):elem{new double[s]}, sz{s} {
} // 实现*我记得类分离实现方法早就有了。这里重点应该是 export 和 module *
用的时候直接 import Vector; 就行了。
其实就是终于适应了 OOP 的办法进行模块化,include 还是古法模块化。
命名空间
命名空间主要用来组织更大规模的程序组件,典型的例子是库。通过使用命名空间,可以很容易地将若干独立开发的部件组织成一个程序。
函数参数与返回值
小小意外但确实,函数也是模块化的重要部分,理应出现在这一章。
函数间信息传递
函数之间信息传递的方式有很多,选择方式的关键考量有:
- 对象是被复制的还是被共享的?
- 这个共享对象是否可被修改?
- 这个对象是否被移动,从而留下了一个空对象?
参数传递和返回值默认行为是复制。不过很多情况下编译器会隐式优化成移动。
返回值
返回引用的情况只应当出现在返回的内容不属于函数局部的时候。
对于大型的对象,复制开销比较昂贵,因此使用移动构造方法。如果不定义移动构造方法,编译器也可以将复制优化为仅在需要时才构建对象——这叫作省略复制优化。
我们不应该为为了这个问题而选择手动管理内存,这是复杂易错的 20 世纪的编程风格喜欢做的事情。
——旧代码喜欢用指针返回大型对象。
还有个 auto 自动推导返回值类型。
有个有意思的,返回类型后置
auto mul(int i, double d) -> double { return i*d; }赞美类型后置!!!
虽然只有一小部分,而且看起来似乎是为了给编译器减负。
结构化绑定
一个函数只能返回一个值,但这个值可以是拥有很多成员的类对象。这往往是函数体面地返回多个值的办法。
有个「解包」语法。
struct Entry {
string name;
int value;
}
Entry read_entry(isream& is) {
string s;
int i;
is >> s >> i;
return {s, i};
}
auto [n, v] = read_entry(is);建议
namespace 用于逻辑隔离,module 用于编译隔离
- 区分声明(用作接口)和定义(用作实现)
- 优先 module 而非头文件
- 用命名空间表达逻辑结构
第4章 错误处理
一个所有语言和所有工程师都要面临的超级大坑摆在面前。
异常
throw 扔一个异常。而编译器实现需要回溯函数的调用栈找到调用者的上下文,然后把异常给感兴趣的调用者,并在过程中调用析构函数。
所以如果没有 try catch,异常会被隐式的向上传递。如果函数不处理异常,就不要写 try catch。
绝大多数的异常可以被简单化,也就是使用 RAII 来减少 try(在其他语言里面要用 final 之类的处理资源,而 C++ 有 RAII 进行系统化的处理,所以很多地方不用写 try,资源会由析构函数自动释放)
约束条件
哲学这块。
函数的行为基于一个满足的基本假定,也就是说任务有其前提条件。比如说传进来的索引不能越界之类的。
对大多数应用来说,检测简单的约束条件是好主意。
当然类也有类约束条件,类约束条件的建立是构造函数的人物。成员函数依赖其并且确保其约束条件的持续。
举例子就是vector定义大小给构造函数的时候总不能传入负数吧。
bad_alloc 是内存分配失败的异常,不过因为现代系统允许分配的内存比实际物理内存更多,所以可能程序都炸鸡几天了 bad_alloc 异常还没被触发。
可以用自定义的类作为异常,这样可以在处理异常时存储更多或更少的信息。并不一定非得使用标准库定义的异常类层次结构。
约束条件和前提条件的好:
- 帮助我们精确理解需求。
- 强迫我们描述得更具体,提升代码书写正确的概率。
其他错误处理方式
没看懂。
抛出异常不是唯一的错误处理方式:
- 抛出异常
- 返回错误代码
- 中止应用程序
返回错误代码的情况:
- 失败很常见而且可以被预期到。比如说打开文件失败。
- 可以期待调用者立即处理这个错误。
- 并行处理的一系列任务发生错误,想知道哪个任务失败了。
- 极低内存的系统中,支持异常机制运行时开销影响了系统核心功能。
还有一个很长的列表说要可以抛出异常的情况,不过我感觉没法吃透。但是我看懂一句话了——如果你不知道用异常还是错误代码,那就用异常。
断言
在当前情况下,没有一个通用的、标准的方法来为诸如约束条件、前提条件等写出可行的运行时检查。然而,对许多大型应用来说,用户需要在测试过程中依赖更高强度的运行时检查,然后在最终发布代码时最小化检查开销。
没看懂!!!感觉还是差了实战经验,断言的使用经验。
assert 是运行时断言。不满足assert的情况下,如果是调试模式的时候则程序中止;非调试模式下,则不进行断言检查。十分简单粗暴。
static_assert 是编译时断言,过不了就报编译错误。
noexcept 是函数声明,如果出现异常的话就直接 std::terminate。
void user(int sz) noexcept建议
- 无法完成既定任务,抛出异常。
- 异常仅用于错误处理而不是正常返回。
- 打开文件失败或迭代结束是预期事件不是异常。和py不一样耶
- 当直接调用者期望处理错误时,使用错误代码。
- 错误需要向上多层函数调用渗透,用异常。
- 不懂用错误代码还是异常,用异常。
- 设计阶段就应该想好异常处理策略。
- 用专门设计的用户自定义类型作为异常。
- 优先 RAII,少用 try。
- 围绕约束条件设计错误处理策略。
- 能在编译时检查的问题就在编译时检查。
- 断言机制进行单点控制。
- 除非全面考虑后,否则不要使用 noexcept。
第5章 类
对于一个程序来说,不论是用易读性还是正确性来衡量,使用一组精挑细选的类写的程序比直接搭建在内置类型上的程序要容易理解得多。而且,往往库所提供的产品就是类。
我们优先考虑对三种重要的类的基本支持:
- 具体类
- 抽象类
- 类层次结构中的类
很多有用的类都可以被归到这三个类别当中,其他类也可以看成是这些类别的简单变形或是通过组合相关技术而实现的。
具体类
类的成员变量可以被限定为私有的(就像Vector一样,2.3节),这意味着这部分内容确实存在,但只能通过成员函数访问。因此,一旦成员变量发生了任何明显的改动,使用者就必须重新编译整个程序。这也是我们想让具体类型尽可能接近内置类型而必须付出的代价。对于那些不常改动的类型,以及那些局部变量提供了必要的清晰性和效率的类型来说,这个代价是可以接受的,而且通常很理想。如果想提高灵活性,具体类型可以将其成员变量的主要部分放置在自由存储(动态内存、堆)中,然后通过存储在类对象内部的成员访问它们。vector和string的机理正是如此,我们可以把它们看成带有精致接口的资源管理器。
讲了个PIMPL (point to implement) 技术,其实在书本前面已经出现过了——虽然原文没说名字。
好像还挺好理解的,需要注意的是具体类是用户自定义类型,也是由内置类型和方法组成,目的是像内置类型一样。
类的内部函数会默认尝试进行内联,当然也可以显式标记 inline。
可以通过实现 std::initializer_list<> 作为传入参数的构造函数来使用 { } 初始化列表进行构造。这个在前文有提到。
抽象类
具体类型的实现属于定义的一部分,而抽象类型则把使用者和类的实现细节完全隔离开,将接口和实现解耦,放弃纯局部变量。
让虚函数 =0 来表示子类必须要实现的虚函数。
和上面 PIMPL 类似,可以将接口和实现分离开,不用因为实现修改而重新编译。
此外,虚函数有个虚表,不过这个很早之前学过,不记了。
类的层次结构
类层次结构的类相较于那些表现形式不复杂、类似于内置类型的类有区别。
可以用 dynamic_cast<A>(p) 来判断指针p是否指向了A的一种类。
适度使用 dynamic_cast 能让代码更简洁。
其次要注意的就是避免资源泄露。(拿了资源不释放)
为了防止资源泄露,不应当用旧式裸指针,而是用 unique_ptr 替代裸指针。
unique_ptr 在离开了作用域的时候,会释放所指的对象。
建议
好多……
- 程序员应该直接用代码表达思想
- 使用具体类表示简单的概念
- 对性能高的组件,优先使用具体类
- 只有当函数确实需要直接访问类的成员变量时,才把它作为成员函数
- 定义操作符的主要目的是模仿它的常规用法
- 把对称的操作符定义为非成员函数(对称指的就是满足交换律)
- 避免裸 new 裸 delete
- 用资源句柄和 RAII 管理资源
- 抽象类不需要构造函数
- 如果要分离接口和实现,就用抽象类作为接口
- 使用指针和引用访问多态对象。
- 设计类的层次结构的时候,注意区分实现继承和接口继承
- 类层次结构导航不可避免的时候,使用dynamic_cast
- 为了防止忘记delete,建议使用 unique_ptr 或者 shared_ptr
第6章 基本操作
初始化、赋值、移动、拷贝
构造函数、析构函数、拷贝操作和移动操作在逻辑上有千丝万缕的联系,在定义这些函数时我们必须考虑它们之间的内在联系,否则就会遇到逻辑问题或者性能问题。 如果类x的析构函数执行了某些特定的任务,比如释放自由存储空间或者释放锁,则该类也应该实现所有其他相关的函数
class X {
public:
X(Sometype); // 「普通的构造函数」
X(); // 默认构造函数
X(const X&); // 拷贝构造函数
X(X&&); // 移动构造函数
X& operator=(const X&); // 拷贝赋值操作符
X& operator=(X&&); // 移动赋值操作符
~X(); // 析构函数
// ...
}编译器会根据需要生成上面这些成员函数,不过「普通的构造函数」除外
当类中含有指针成员时,最好显式地指定拷贝操作和移动操作。如果不这样做,则当编译器生成的默认函数试图delete指针对象时,系统将发生错误。即使我们不想delete某些对象,也应该在函数中指明这一点,以便于读者理解。例子可以参见6.2.1节。好的经验法则(有时叫作零法则)是要么定义所有的基本操作,要么不定义任何操作(全部使用默认设置)。
让函数 =default 显式声明使用基本函数的默认实现(而不是被优化)
同样可以用 =delete 来声明不生成目标操作函数。使用 =delete 的函数会在编译时报错,并且 =delete 可以用于禁用任何函数。
如果有单个参数构造建议用explict修饰函数,不然容易引发意料之外的隐式类型转换。
拷贝和移动
拷贝就略了,这个老版本也有,就是复制一份内存数据。
C++11的新特性,T&& 表示的是右值引用,T& 表示的是左值引用。而多重引用&&&&&&... 会发生引用折叠,从引用的引用变成一层引用。
左值引用和右值引用我以前还真没听说过耶。
发生移动时原来的对象会被清空,而数据会被转移到新对象上。
可以用 std::move(a) 来获得 a 的右值引用。
资源管理
从本质上来说,垃圾回收是一种全局内存管理模式。适当使用当然没有问题,不过随着系统的分布式趋势(比如多核、缓存及集群)日益明显,在局部范围内管理资源变得越来越重要了。
C++ 标准库中, RAII 无处不在。
需要注意的是,资源管理不止是内存资源,也包括非内存资源比如说文件读写资源等等。
操作符重载
好像也没什么好记的。
需要注意的是,尽量让重载的方法符合操作符原本的直观定义。
有一个 C++ 20 的新操作符:「宇宙飞船操作符」——<=> (其实是「三向比较运算符」)
其含义大概是:两个数比较,如果大于的话返回一个正数,如果小于的话返回一个负数,如果等于的话返回 0
在定义了默认的⇐>操作符后,其他关系( < > ⇐ >= == !=)操作符会被隐式定义。
class R {
// ...
auto operator<=>(const R& a) const = default;
};
void user(R r1, R r2) {
bool b1 = (r1 <=> r2) == 0; // r1 == r2
bool b1 = (r1 <=> r2) < 0; // r1 >= r2
bool b1 = (r1 <=> r2) > 0; // r1 <= r2
}
如果是自行重载的⇐>操作符,那么需要手动定义 运算符。(通常 都是能手动进行优化的)
常规操作
0. 0
用户自定义字面量 UDL
自定义的字面量用后缀来区分。
比如说 “Surprise”s 是 std::string 类型,12.7i 可以表示 imaginary 类型
通过定义字面量操作符来实现。
constexpr complex<double> operator""i(long double arg) {
return {0, arg};
}底下 return 的东西用到了 列表初始化 + 拷贝消除(返回值初始化RVO)
建议
- 尽量让对象的构造、拷贝、移动、销毁都在掌握中。
- 设计构造、赋值、析构函数时要全盘考虑,使之成为一体。
- 同时定义所有基本操作,或者什么都不定义。
- 尽量把单参数的构造函数声明成 explicit 的。
- 用传值的方式返回容器(依赖拷贝消除和移动以提高效率)
- 对于容量较大的操作数,用 const 引用作为参数类型。
- 避免显式使用 std::copy()
- 用 RAII 管理所有资源——内存和非内存资源。
- 如果将类型的 ⇐> 定义为非默认值,那么也要定义 == 操作符
- 遵循标准库容器设计
第7章 模板
模板是一个类或者一个函数,我们用一组类型或值对其参数化。我们使用模板表示那些通用的概念,然后通过指定参数生成特定的类型或函数。
跟泛型有点像,写粗略了。
用 template<typename T> 在 class 声明前面就能使用模板。
typename T 和 class T 意思都一样,class T 主要是来自于旧式代码。
参数化类型
受限模板参数
可以用 C++20 的 概念 来对模板参数进行限制。
概念检查纯粹在编译时进行。
C++在C++20标准之前并没有官方支持概念,所以旧有代码只能使用受限模板参数,并且把受限需求写在文档中。然而,从模板生成的代码同样包含了类型检查,即便是受限模板的代码也和手写代码一样类型安全。
模板值参数
就是用具体的值当模板参数。
例如:template<typename T, int N>
不幸的是,因为隐晦的技术原因,字符串字面量不可以作为模板值参数。但在某些场合,使用字符串值作为参数又非常重要。因而,我们可以使用存放字符的数组来表示字符串:
无力吐槽。
在C++中,通常会有间接的解决方案:不需要对所有情况提供直接支持。
吐槽被预判了。。。
模板参数推导
模板参数会自动推导。
当初始化列表的类型不一致时编译器会报出二义性错误。
不过不是很理解干嘛喜欢隐式模板参数,显式指定大部分情况都表现足够良好。
如果要解决二义性问题可以用 推导指引 。
template<typename Iter>
Vector(Iter,Iter) -> Vector<typename Iter::value_type>可以理解为手动指定当遇到特定类型的时候,使用什么模板参数。
推导指引的效果往往很微妙,所以最好在模板类中通过设计来避免必须使用推导指引的情形。
我也觉得很微妙。
此外喜欢名词和缩写词的,可以把「类模板参数推导」缩写成 CTAD。我也不懂为什么作者要强调这个,可能作者不喜欢缩写词吧。
参数化操作
要想表达将操作用类型或者值来参数化,有三种方法:
- 模板函数
- 函数对象:对象可以带数据,并以函数形式调用
- 匿名函数表达式:函数对象的简略记法。
模板函数
跟类模板差不多,就是模板化的函数。
函数对象
用class来模拟函数,重载了operator()并且能携带数据,当然也可以用类模板的办法来参数化。
匿名函数表达式
函数对象可以用来写明通用算法中的关键操作(比如Less_than对象与count()算法的关系),它有时也被叫作策略对象。
匿名函数表达式可以用 [&](int a){ return a<s; } 这样的语法来表达。
其中,[&] 是匿名函数的捕获列表,指定了函数体内所有局部变量可以以引用形式访问。如果要拷贝,可以以[=]以值方式捕获所有,以[]不捕获,以[&x]表示只以引用方式捕获x。以[i,this] 捕获多个对象。
匿名函数表达式当然也可以参数化。
template<class S>
void rotate_and_draw(vector<S>& v, int r) {
for_each(v, [](auto& s){ s->rotate(r); s->draw(); });
}这里 auto 表示可以接受任意类型。
需要注意的是,含有 auto 参数的匿名函数也是模板,也叫 泛型匿名函数。
我查了一下,函数参数用 auto 这个有点说法和历史的。C++11 不支持 auto。C++14/17 仅支持 lambda 表达式(也就是匿名函数)的 auto 参数,而到了 C++20 引入 缩写函数模板 语法糖后,才支持在非匿名函数中使用 auto 参数。C++20 里面在非匿名函数中使用 auto 会自动转换成模板函数。
使用匿名函数,可以将任意语句变成表达式。
如果遇到了不含析构函数的对象(例如 C 代码),可以使用作用域终结函数(用匿名函数来实现的)来处理。
[[nodiscard]] auto finally(F f) 大概实现思路就是用一个类 Final_action 来包装原来不会析构的对象,而 Final_action 自身定义了析构函数,并且在析构函数中用 free 对包装的对象进行析构。(怎么感觉某种角度复刻了智能指针,只不过构造是用的匿名函数包装了类的构造)
[[nodiscard]] 属性修饰函数,确保用户不会忘记保存生成的返回值 Final_action.
代码如下:
template<class F>
[[nodiscard]] auto finally(F f) {
return Final_action{f};
}
template<class F>
struct Final_action {
explict Final_action(F f): act(f) {}
~Final_action() { act(); }
F act;
}
// 调用时
finally([&]{free(p);}) // 离开作用域时自动调用匿名函数,使用 free 释放模板机制
想定义好的模板,我们需要一些支撑性的语言设施。
- 依赖类型的值:模板变量(这里似乎是笔误,原文说的是参数模板,但是指向的底下标题却是「模板变量」)
- 类型与模板的别名:别名模板
- 编译时选择机制:
if constexpr - 编译时查询值与表达式属性的机制:
requires表达式
除此外,constexpr 函数 和 static_asserts 也经常出现在模板设计和使用中。
模板变量
依赖模板类型的常量或变量
template<class T>
constexpr T viscosity = 0.4;
template<class T>
constexpr space_vector<T> external_acceleration = { T{}, T{-9.8}, T{} };
auto vis2 = 2*viscosity<double>;
auto acc = external_acceleration<float>;这是 C++14 出的功能。
标准库使用模板变量来提供数学常数,比如说 pi 以及 log2e.
别名
可以这么起别名。
using size_t = unsigned int;意思是 size_t 是 unsigned int 的别名。
有参数的模板类型经常针对特定参数提供特定别名。
template<typename T>
class Vector {
public:
using value_type = T;
// ...
}
template<typename C>
using Value_type = C::value_type;
template<typename Container>
void algo(Container& c) {
Vector<Value_type<Container>> vec;
}*我查了一下,C++20有适用于 Range 的简略写法。不过讨论回记录类型本身,其实可以省略中间变量,只要 C++11 以上就能用的语法 Vector<typename Container::value_type> vec; *
此外别名也可以通过绑定模板的部分参数来定义新的模板。
template<typename Key, typename Value>
class Map {
// ...
}
template<typename Value>
using String_map = Map<string,Value>
String_map<int> m; // Map<string,int>编译时 if
使用编译时 if 让模板决定根据具体类型使用哪种方案。
void update(T& target) {
// ...
if constexpr(is_trivially_copyable_v<T>)
simple_and_fast(target); // 对于 PDO 类型
else
slow_and_safe(target); // 对于复杂类型
//...
}is_trivially_copyable_v<T> 是一个类型谓词,表明类型是否可以以较小的代价被拷贝。
编译器只会编译所选择的 if constexpr 分支。这个方案提供了最佳性能以及最佳的局部性。
此外需要注意的是这不是编译器宏,所以 if constexpr 不是文本处理机制。
建议
- 用模板表达那些用于多种参数类型的算法。
- 用模板实现容器。
- 模板是类型安全的,但是对于无约束的模板,检查发生得太晚了。
- 把函数对象作为算法的参数。
- 如果简单的函数对象只在某处使用一次,不妨使用匿名函数。
- 不能把虚函数成员定义成模板成员函数。
- 使用 finally() 为不带析构函数且需要「清理操作」的类型提供 RAII;
- 使用 if constexpr 条件编译提供替代实现,不会存在运行时开销。
第8章 概念和泛型编程
C++20 超新特性。当然对于这本书来说是超新,对于这篇博客来说已经是 5 年前了。
应该把模板用在哪儿呢?换句话说,模板会让哪些程序设计技术更有效呢?模板提供了以下功能:
- 在不丢失信息的情况下将类型(以及值和模板)作为参数传递的能力。这意味着可以表达的内容具有很大的灵活性以及具有内联的绝佳机会,当前的实现充分利用了这一点。
- 有机会在实例化时将来自不同上下文的信息捏合在一起,这意味着有进行针对性优化的可能。
- 把值作为模板参数传递的能力,也就是在编译时计算的能力。
总而言之,模板为编译时计算和类型控制提供了强有力的机制,使得我们可以编写出更加简洁高效的代码。记住,类可以包含代码和值。
模板的最常见应用是支持 泛型编程(generic programming),泛型编程主要关注通用的算法设计。
原来 generic 是指通用,虽然这么说好像在说原来 apple 是苹果一样奇怪,但我还是去想泛型编程的作用而不是当只知道凭直觉用。
概念
使用概念来进行模板参数的限定。
例如 range_value_t<Seq> 表示的是序列中的元素类型。Arithmetic<X,Y> 则表示 X 和 Y 能进行算术运算。
概念可以这么使用。
template<Sequence Seq, Number Num>
requires Arithmetric<range_value_t<Seq>, Num>
Num sum(Seq s, Num n);
requires Arithmetric<range_value_t<Seq>, Num>被称作requirements子句。
谁发明的「概念」,「requirements子句」这都要起别名吗。
template<Sequence Seq> 就是 requires Sequence<Seq> 更简单的写法。
不支持 concept 的代码,可以把代码用注释的形式写出来:
template<typename Seq, typename Num>
// requires Arithmetic<range_value_t<Sequence>,Number>
Num sum(Seq s, Num n);难蚌,真就人脑一个编译器了。不过重点还是把模板设计的约束条件写清楚。
基于概念的重载
就是用概念不同来重载。编译器会选择满足最严格参数需求的版本。
标准库 advance() 函数向前移动迭代器。
template<forward_iterator Iter>
void advance(Iter p, int n) {
while (n--) ++p;
}
template<random_access_iterator Iter>
void advance(Iter p, int n) {
p += n;
}跟其他的重载一样,这是编译时机制,没有任何运行时开销,如果编译器找不到最佳选择,就会报告二义性错误。基于概念的重载比一般的重载效率更高。
有效代码
这下知道为什么要起名了。
不使用标准库的概念 random_access_iterator 而是手动实现的话,可以是这样:
template<forward_iterator Iter>
requires requires(Iter p, int i) { p[i]; p+i; } // Iter 拥有下标操作以及整数操作
void advance(Iter p, int n) {
while (n--) ++p;
}第一个 requires 开始一个 requirements 子句,第二个 requires 开始一个 requires 表达式。
第二个 requires 表达式是一个谓词,如果代码为有效代码则为 true,否则为 false。
我认为requires表达式可以被叫作泛型编程中的汇编代码。与常规汇编代码一样,requires子句非常灵活,并且不隐含任何编码规则。从某种程度上说,它是泛型编程中的底层代码,如同说汇编代码是普通编程的底层代码一样。因此,与汇编代码类似,requires子句不该出现在常规代码中。它们应当隐藏在抽象的具体实现中。如果你在你的代码中看到了requires requires子句,很可能这样的代码过于底层,最终可能产生潜在问题。
没得喷,这个设计确实神。
上面那段 requires requires 代码是刻意的、不优雅的黑客行为。
定义概念
终于要来了吗,我很好奇为什么要把定义概念放在应用概念后。甚至早在模板那章就提及概念使用而不是概念定义——让当时的我我一头雾水。
直接用库的优秀概念比写新的要容易。不过写新的概念也很容易。
概念是一个编译时谓词,指示了一个或多个类型如何被使用。
template<typename T, typename T2=T>
concept Equality_comparable =
requires (T a, T2 b) {
{ a == b } -> Boolean; // 使用 == 比较 T 类型变量
{ a != b } -> Boolean;
}Boolean 意味着类型也能作为条件。
typename T2=T 表示没有指定第二个模板参数和T相同,称为 默认模板参数。
定义数字概念:
template<typename T, typename U=T>
concept Number =
requires(T x, U y) {
x+y; x-y; x*y; x/y;
x+=y; x-=y; x*=y; x/=y;
x=x; // 拷贝
x=0;
}Arithmetic 概念:
template<typename T, typename U=T>
concept Arithmetic = Number<T, U> && Number<U, T>;模板产生的检查会从模板定义推迟到模板实例化时,好处是:
- 在开发过程中使用不完整的概念,允许在开发过程中积累经验,渐进式地完善检查。
- 可以将调试信息、跟踪信息、遥测信息等代码插入模板,而不会影响它的接口。
接着便是先前我想到过的 auto 关键字。在 C++20,函数里面的 auto 参数会让函数自动变成函数模板。
可以用概念修饰 auto。
Arithmetic auto twice(Arithmetic auto x) { return x+x; }泛型编程
概念并不仅仅是一个语法记法,也是描述语义的基本要素。目前并没有任何语言支持用来表示语义,所以只能依赖专业知识和大众公式来确保概念语义的正确。
从一段或者几段实体代码生成一段泛型代码的同时保持原有性能,这种行为叫作提升 (lifting)。从而,最佳的开发模板的方法通常是:
- 首先,写一个实体代码版本。
- 调试,测试,然后测量它们。
- 最后,将实体类型转化为类模板参数。
可变参数模板
举例是 print:
template<Printable T, Printable... Tail>
void print(T head, Tail... tail) {
cout << head << ' ';
if constexpr(sizeof...(tail)> 0)
print(tail...);
}参数声明后面的 ... 叫作参数包。
还有折叠表达式
template<Number T>
int sum(T... v) {
return (v + ... + 0);
}这里是右折叠,从零开始,最先做运算的是最右边的元素。
左折叠的写法是 (0+...+v) .
折叠表达式目前仅限用于简化可变参数模板的实现。
建议
- 模板为编译时编程提供了通用设计
- 把概念作为设计工具
- 避免使用不含有效语义的概念
- 模板提供编译时的鸭子类型
第9章 标准库
为了避免有歧义风险,因此后缀不能显式限定,只能将一组后缀引作用域。所以,一个库如果要与(可能定义了自用后缀的)其他库一同使用,通常需要将后缀定义到子命名空间。
ranges 命名空间
标准库提供的算法有两个版本:
- sort(begin(v), v.end())
- sort(v)
特殊的,为了避免使用非限定模板时造成的歧义,标准规定了范围版本必须在作用域内显式声明。
using namespace std;
void g(vector<int>& v) {
sort(v.bgein(),v.end());
ranges::sort(v);
using ranges::sort;
sort(v);
}建议
- 不要重新发明轮子,应该使用库。
- 当有选择时,优先选择标准库而不是其他库。
- 不要认为标准库在任何情况下都是理想之选。
- 使用 ranges 时,显式限定算法名称。
- 如有可能,尽量用 import 模块代替
#inclued头文件。
第10章 字符串和正则表达式
C++ 有 string 类型,也有 string_view 类型——以容器方式访问字符序列,不论是在 std::string 还是 char[]。
string 和 regex 都支持多种字符类型比如说 unicode.
string 类型
用 + 可以对字符串进行链接。string 定义了移动构造函数,所以用传值方式返回也同样高效。
string.substr 提取子串,string.replace 替换,toupper 大写。
可以用[]索引 string,at() 类似。
可以和 string、c风格字符串、字面量比较。
用 c_str() 和 data() 可以以 c风格字符串 只读访问 string 的内容。
string 类型字面量的后缀是 s (std::literals::string_literals)
字符串实现
用了 短字符串优化技术 SSO,意思是短字符串会被存在 string 对象内部,长字符串会被存在 自由存储 中。
不过标准没规定要多少字符就扔自由存储,这要看具体实现。
为了处理多字符集,标准库给了一个通用的字符串模板 basic_string , string 实际上是这个模板的实例化 using string = basic_string<char>;
字符串视图
字符串视图出现,是为了解决未出现在标准库(即自定义)字符串类型传递子串的问题。string_view 本质上是(指针,长度)对,标明了一个字符串序列。
string_view 是只读的。如果想要写版本的,用 span。
string_view 要当成指针用,因为可能会造成越界访问。
at() 会产生异常。
string_view bad() {
string s = "Once upon a time.";
return {&s[5], 4};
}返回前 s 就已经销毁了。
正则表达式
<regex>
一个例子是这样:
regex pat {R"(\w{2}\s*\d{5}(-\d{4})?)"};R"()" 这种就是 原始字符串字面量 raw string literal。这种原始字符串字面量不用转义。
regex_match 正则和字符串匹配 regex_search 搜索和正则匹配的字符串 regex_replace 替换 regex_iterator 遍历匹配结果和子匹配 regex_token_iterator:遍历未匹配部分
正则表达式的语法和语义的设计目标是使之能被编译成可高效运行的自动机[Cox,2007],这个编译过程是由regex类型在运行时完成的。
用的是 ECMA 标准的变体
可以用 regex_iterator 遍历流。using sregex_iterator = regex_iterator<string>.
建议
- 返回 string 应用传值方式,依赖移动语义和拷贝消除
- 直接或间接使用 substr() 和 replace() 操作子字符串
- 使用范围 for 来安全地降低越界检查要求
- 需要用范围检测时,用 at() 而不是 []
- 当需要优化性能的时候,应该使用 [] 而不是 at()
- 只有迫不得已的时候,采用 c_str() 和 data()
- 输入放进 string 不会溢出。 肯定啊,有 SSO
- 使用 stringstream 或者更通用的值提取函数(
to<X>) 将字符串转换为数值。 - 可以用 basic_string 构造适用于任何类型字符组成的字符串。
- 字符串字面量后面加 sv 可以表示标准库 string_view 类型字面量。
- 将 regex 用于正则表达式的大部分常规用途。
- 使用正则表达式注意节制,它很容易变成难懂的语言。
- 用 regex_iterator 来遍历流并查找给定模式
第11章 输入和输出
I/O 流库提供了文本和数值的输入输出功能,这种格式化和非格式化的输入都带有缓冲。它提供了类型安全,同时也可以扩展为像支持内置类型一样支持用户自定义类型。
文件系统库提供了操作文件和目录的基本工具。
标准库流可以用于二进制 IO、用于不同字符类型、用于不同区域设置,也可以用高级缓冲策略。 但是这本书不讲,超出讨论范围了。
流可以往标准库 string 输入和输出数据,或者往 string 缓冲区写格式化的数据,或者往内存区域写,或者往文件 IO 写。
输入和输出都有析构函数,可以释放拥有的资源(比如缓冲区和文件句柄)。也是 RAII 的示例。
输出
<ostream>
cout 是标准输出流,cerr 是报告错误的标准流。通常写入 cout 的值被转换成字符序列。
输出表达式的结果是输出流的引用,所以可以用来继续输出,也就是:
cout << "the value of i is" << i << "\n";注意,输出一个字符的结果就是其字符形式,而不是数值:
int b = 'b'; // char 隐式转 int
char c = 'c';
cout << 'a' << b << c; // a98c输入
<istream>
感觉 cin cout 只是包装了 scanf 和 printf. 能够少写格式化字符串而已.
可以用 getline() 来获取一整行。
使用格式化 IO 操作不那么容易出错,而且更有效率。特别地,istream 会处理好内存管理和范围检查。可以从字符串流和内存流写入或读出格式化的内容。
I/O 状态
每个 iostream 都有状态,可以通过这个状态来判断流操作是否成功。
比如说读取序列:
vector<int> read_ints(istream& is) {
vector<int> res;
for (int i; is>>i;) {
res.push_back(i);
return res;
}
}is >> i 返回是 istream 引用, iostream 对象流结果为 true 的话,表示流已经准备好进行下一个操作。
iostream状态 包含了读写所需要的所有信息。比如说格式化信息、错误状态、缓冲。此外,也可以认为设置状态来表示错误,或者人为清除状态。 iostream.setstate() iostream.clear().
用户自定类型的 I/O
就重载 << 和 >> 就可以了
输出格式化
iostream 和 format 都能控制输入输出的格式。iostream 和 C++ 历史一样悠久,风格是格式化算术数字组成的流。format 是 C++ 20 的新库,风格则是 printf() 规格来格式化。
流格式化
流的格式化可以用 格式控制符。
cout << 1234 << ' ' << hex << 1234 << ' ' << oct << 1234 << dec << 1234 << '\n';
// 1234 4d2 2322 1234也可以设置浮点格式比如说 scientific hexfloat fixed defaultfloat.
用 cout.precision(n) 设置精度,在输出时会小数会进行四舍五入。
浮点格式控制符都是「黏性的」,也就是会在后续浮点值输出中都有效。
printf() 格式化
c语言的 printf 缺乏类型安全。在 <format> 中,提供了类型安全的 printf.
string s = format("Hello, {}\n", val);格式化字符串 后续 {} 和参数会决定如何格式化字符串。
cout << format("{} {:x} {:o} {:d} {:b}\n", 1234,1234,1234,1234,1234,1234);这样可以指定格式。 x 代表整数.
cout << format("{3:} {1:x} {2:o} {0:b}\n", 000, 111, 222, 333);冒号前面的数字则指定了使用的参数顺序。(也提供了可以多次使用同一参数的可能)
format 浮点数格式化和流的浮点数格式化差不多:
- e 科学记数法
- a 十六进制
- f 定点
- g 默认 这什么鬼缩写,global 吗
format() 提供了一种迷你语言,大约有 60 种格式化描述符。
vformat() 接受变量作为格式,更加灵活,也更容易报错。
到最后我还是没看懂类型安全在哪里,仅仅是把 format 拆成了 format 和 vformat,该报错 vformat 还是报错,对自定类型也不友好。
流
标准库直接支持下面的流:
- 标准流
- 文件流
- 字符串流
- 内存流
- 同步流:在多线程使用时避免数据竞争的流
也可以自己定义流,比如说通信通道的流。
流不可以被拷贝,只能用引用传递.
标准库流都是模板,参数是字符类型,也就是 using ostream = basic_ostream<char>. 支持 unicode 的宽字符流是 basic_ostream<wchar_t>.
标准流
- cout 普通输出
- cerr 无缓冲错误输出
- clog 有缓冲日志输出
- cin 标准输入
文件流
<fstream>.
- ifstream 从文件读取数据
- ofstream 向文件写入数据
- fstream 用于读写
ofstream ofs {"target"};
if (!ofs)
error("couldnt open 'source' for reading");字符串流
<sstream> 提供了从 string 读取数据以及向 string 写入数据的流。
- istringstream 从 string 读数据。
- ostringstream 向 string 写数据
- stringstream 读写 string.
ostringstream.str() ostringstream.view().
ostringstream 常见用途是对输出内容格式化,然后再输出到 gui. 反之则可用 istringstream 从 gui 读取格式化输入。
内存流
从早期的C++开始,就有由用户设计的内存流,这样可以直接通过流来读写内存。这类流的最古老实例,比如strstream,数十年前就已经被废弃了,而它们的替代品,spanstream、ispanstream,以及ospanstream,在C++23之前还没有成为官方标准。虽然如此,但它们已经被广泛使用,你可以试试你的C++实现是否支持它们,或者自行搜索GitHub以寻找第三方实现。
如果尝试将目标缓冲写溢出,那么目标的状态会变为 failure.
同步流
多线程 I/O 可能会变得不可靠,除非:
- 只有一个 thread 在使用流.
- 访问流的操作进行了同步,确保同一时刻只有一个 thread 获得访问权.
osyncstream 可以保证系列操作都可以完成,举例如下:
void unsafe(int x, string& s) {
cout << x;
cout << s;
}不同的 thread 会引发数据竞争,osyncstream 类型可以避免。
void safer(int x, string& s) {
osyncstream oss(cout);
oss << x;
oss << s;
}所有 thread 同时使用 osyncstream 就能保证不会互相影响。所以要么统一所有线程用 osyncstream,不然就只有一个 thread 用输入输出流。
多线程同步需要一些技巧,因此请特别注意(第18章)。只要可能,就应当避免数据在 thread 之间共享。
C 风格 I/O
也就是 C 标准库的 I/O.
省流:不建议使用。
如果不使用 C 风格 I/O 并且在意 I/O 性能的话,可以用
ios_base::sync_with_stdio(false);文件系统
不幸的是,文件系统的属性和操作它们的方式差异很大。为了解决这个问题,文件系统库
<filesystem>为大多数文件系统的大多数工具提供了统一的接口。
通过 filesystem 可以可移植的实现:
- 表达文件系统路径,在文件系统导航
- 检查文件类型和附加的权限许可
path f = "dir/hello.cpp"
assert(exists(f));
if (is_regular_file(f))
cout << f << " is a file. its size is " << file_size(f) << '\n';请注意,操作文件系统的程序通常与其他程序一起在计算机中运行。因而,在两个命令之间,文件系统的内容可以发生变化。例如,即使我们首先小心翼翼地断言f存在,但在下一行时,如果我们询问f是否是一个常规文件,这可能不再为真。
path 是一个很复杂的类,能够处理各种各样的字符集。
部分遍历目录和查询文件的类:
| 类名 | 备注 |
|---|---|
| path | 文件路径 |
| filesystem_error | 文件系统异常 |
| directory_entry | 目录项 |
| directory_iterator | 遍历目录 |
| recursive_directory_iterator | 递归遍历目录 |
太长不写了,知道有这么一个标准库就行了,用到再查。
建议
- iostream 是类型安全、类型敏感、易扩展的。
- 必要时才用字符级输入
- 读取输入数据的时候,总要考虑格式不正确的输入
- 避免 endl (如果你不知道 endl 是什么,你就没有错过任何东西). 何意味?查了一下,说的是 endl 会强制冲刷输出缓冲区. 冲刷缓冲区性能开销可能是昂贵的。
第12章 容器
大多数计算任务都会涉及创建值的集合,然后对这些集合进行操作。一个简单的例子是读取字符并存入 string 中,然后打印这个 string。如果一个类的主要目的是保存对象,那么我们通常称之为 容器container。对给定的任务提供合适的容器及其上有用的基本操作,是构建任何程序的重要步骤。
vector
最有用的标准库容器当属vector(动态数组)。vector就是一个给定类型元素的序列,元素在内存中是连续存储的。典型的vector实现(5.2.2节、6.2节)会包含一个句柄,保存指向首元素的指针,还会包含指向尾元素之后位置的指针以及指向所分配空间之后位置的指针(或者是等价的指针外加偏移量)(13.1节):
vector 包含了一个分配器 alloc,vector 通过分配器为元素分配内存空间。默认的分配器用 new 和 delete 分配和释放内存。
vector 的元素构成了一个范围,可以使用范围 for 语句。
可以用圆括号进行另一种初始化:
vector<Shape*> v3(23); //尺寸 23, 初始值 nullptr
vecotr<double> v4(32, 9.9); // 尺寸 32, 初始值 9.9标准库vector非常灵活且高效,应当将它作为默认容器。也就是说,除非有充分的理由使用其他容器,否则应使用vector。如果你的理由是“效率”,请进行性能测试一一我们在容器使用性能方面的直觉通常是很不可靠的。
list
标准库提供了名为 list 的双向链表。
用链表时,通常不会像用数组那样用它,也就是说不常用下标操作访问,而是搜索给定值。所以链表也可以用范围 for 遍历。
上面这些 list 的例子都可以等价地写成使用 vector 的版本,而且令人惊讶的是(除非你了解机器的体系架构),vector 的性能经常会优于 list。当想要一个元素序列时,我们面临 vector 与 list 之间的选择。但除非你有充分的理由选择list,否则就应该使用 vector。vector 无论是遍历(如,find()和count())性能还是排序和搜索(如,sort()和 binary_search(),13.5节、15.3.3节),性能都优于list。
不太懂为啥,我猜也许是因为连续存储易于随机访问和修改导致的吗,而 vecotr 顺序访问则会因为连续而被机器优化执行所以相同甚至更高性能。不论如何,说的大概率是非常有道理和有用的话。
forward_list
经典的单向链表。
单向链表。
这个设计的目的是为了比 list 更省空间,但是只允许向前迭代。
map
原来 map 底层是平衡二分搜索树而不是散列表。
标准库提供了名为 map 的平衡二分搜索树(通常是红黑树)。
map 也被称为关联数组或字典。
map<string, int> phone_book {
{"Tom", 123};
{"Ammy", 234};
}
int get_number(const string& s) {
return phone_book[s];
}map 下标操作本质是搜索,如果没有找到 key 就会进行插入。
误会你了,map。我一直以为这个 map 是用散列表实现的。
如果希望避免添加无效号码到电话簿中,应该使用 find() 和 insert() 代替 [].
unordered_map
还有高手,原来这才是散列表.
搜索 map 的时间复杂度是 O(log(n)). n 是 map 中的元素数目。虽然通常情况这个性能已经很好了,但是还可以更好——那就是用哈希查找。
标准库哈希容器是无序容器,不需要顺序比较函数。
标准库有默认的哈希函数,在必要的时候,用户也可以定义自己的哈希函数。
在给定了优秀的哈希函数的情况下,unordered_map 比 map 快得多,尤其是对大型容器而言。
分配器
内存管理 + 容器 = 经典优化魔法
默认标准库容器用 new 和 delete 分配空间。这很好,但是某些情况会带来性能问题。
假定有一个重要的、长时间运行的系统,其使用事件队列(18.4节)并且使用vector作为事件存储容器,元素以shared_ptr保存。在这种情况下,事件的最后一个用户会隐式地释放该事件:
struct Event {
vector<int> data = vector<int>(512);
}
list<shared_ptr<Event>> q;
void producer() {
for (int n = 0; n!=LOTS; ++n) {
lock_guard lk {m}; // 互斥信号量
q.push_back(make_shared<Event>());
cv.notify_one(); // 条件变量
}
}从逻辑上说,这样应该工作得很好。具备清晰的逻辑,代码也健壮、可维护。不幸的是,这会导致大量的内存碎片。当16个生产者与4个消费者处理了10万个事件后,6GB以上的内存被碎片吞噬。
经典碎片内存,所以对于长时间运行的系统,还是不能随便 new delete啊。
解决碎片问题的传统方案是使用内存池分配器重写代码。内存池分配器用来管理固定尺寸空间分配,并且一次性分配大量的对象,而不是每次申请单独分配。幸运的是,C++直接支持这个功能。内存池分配器定义在std命名空间的pmr(多态内存资源)子空间中:
pmr::synchronized_pool_resource pool;
struct Event {
vector<int> data = vector<int>{512, &pool};
}
list<shared_ptr<Event>> q {&pool};
void producer() {
for (int n = 0; n!=LOTS; ++n) {
lock_guard lk {m}; // 互斥信号量
q.push_back(allocate_shared<Event,pmr::polymorphic_allocator<Event>> {&pool});
cv.notify_one(); // 条件变量
}
}太深奥了,感觉得看多态内存相关补一下了后面……好吧,我脑抽了,这个多态内存资源就如其名了,其实是内存的多态释放和分配。std::pmr::memory_resource 类提供了一个接口,可以通过这个接口来进行多态的内存释放和分配,适应多样化的内存性能需求。
多态内存资源必须从 memory_resource 派生,并且定义了成员函数 allocate()、deallocate() 和 is_equal().
容器概述
| 容器名 | 内容 |
|---|---|
vector<T> | 可变尺寸数组 |
list<T> | 双向链表 |
forward_list<T> | 单向链表 |
deque<T> | 双端队列 |
map<K,V> | 关联数组 |
multimap<K,V> | 关键字可重复的 map |
unordered_map<K,V> | 哈希查找实现的 map |
unordered_multimap<K,V> | 哈希版本的多值 map |
set<T> | 只有关键字没有值的 map(集合) |
multiset<T> | 值可以出现多次的集合 |
unordered_set<T> | 哈希版本的集合 |
unordered_multiset<T> | 哈希版本的多值集合 |
标准库还提供了容器适配器比如说 queue<T> stack<T> priority_queue<T>. 还有定长数组 array<T,N> 和 bitset<N>. |
草了,好多细节。
注意一下 emplace_back 和 push_back 区别吧。
emplace操作(比如emplace_back())获取元素构造函数的参数,并在容器中新分配的空间中直接构建对象,而不是将对象拷贝到容器中。例如,对于vector<pair<int,string>>类型,我们可以这样写:
v.push_back(pair{1,"copy or move"}); // 赋值或者移动构造
v.emplace_back(1, "build in place"); // 就地构造不过上面这种简单情况,优化器会优化成同等性能。
建议
- 标准库容器定义一个序列
- 标准库容器是资源句柄
- 对于容器的简单遍历,使用范围 for 循环或者一对 begin/end 迭代器。
- 使用 reserve() 可以避免指向元素或指针迭代器失效。
- 如果需要进行范围检查,应使用 at().
- 对容器用 push_back() 和 resize(),而不是 realloc().
- 元素是被拷贝到容器中的.
- 如果要保持元素的多态行为,可以在容器中保存指针。 也就是说,保存基类的指针,这样就可以存储各种基类的派生类,达到多态。
- vector 上执行插入操作,insert() 和 push_back() 可能比预期更高效。
- 对通常为空的序列使用 forward_list.
- 事关性能时,不要相信你的直觉,应该进行性能测试。
- map 通常使用红黑树实现。
- unordered_map 是哈希表。 周树人是鲁迅。
- 传递容器时,传递引用;返回容器时,应返回值。
- 优先选择紧凑的、连续存储的数据结构.
- 没有顺序就用无序容器。
- 通过实验来检查你设计的哈希函数是否令人满意.
- 将多个标准哈希函数用异或操作符组合设计成的哈希函数通常有较好的效果.
- 如果遇到了内存相关的性能问题,尽量减少使用自由存储和/或考虑使用专门的分配器.
第13章 算法
标准库除了提供常用的容器类型以外,还为容器提供了常用的算法。
标准库算法都被描述为元素序列(半开半闭区间)上的操作, 序列 用一组迭代器表示。
不幸的是,标准库没有提供抽象来支持范围检查的写入。
迭代器
pass
迭代器类型
迭代器的本质是什么?
省流:迭代器是一个泛型,也是一个 concept. 符合迭代器特征的都是迭代器.
用户很少知道特定迭代器的类型,容器知道自己迭代器的类型,并且以规范定义的 iterator 和 const_iterator 给用户使用。
有些情况下,迭代器不是成员类型,所以标准库提供了 iterator_t<X> 函数来统一接口,对定义的迭代器类型 X 可用。
流迭代器
istream_iterator<> ostream_iterator<>
使用谓词
这回真是谓词了,函数式的那种。
void f(map<string,int>& m) {
auto p = find_if(m, Greater_than{42}); // 谓词 Greater_than{}.
}Greater_than 是函数对象.
struct Greater_than {
int val;
Greater_then(int v) : val{v} {}
bool operator() (const pair<string,int>& r) const {
return r.second > val;
}
}匿名函数也可以.
auto p = find_if(m [](const auto& r) { return r.second > 42 });标准库算法概览
懒得全部记完,记一些特殊的.
| name | note |
|---|---|
| for_each | 遍历执行 f(x) |
| find_if | 如果满足 f(x) |
| count_if | 计数和if |
| replace_if | |
| copy_if | |
| move | |
| unique_copy | 不拷贝连续重复元素 |
| sort | 可以多加一个 f(x) 谓词作为排序标准 |
(p1,p2)=equal_range(b,e,v) | [pl:p2)是已排序序列[b:e)的子序列,其中元素的值都等于v:本质上等价于二分搜索v |
| merge | 归并序列,并将归并序列存到新序列。可以加 f(x) 作为比较函数 |
每个算法都有 <range> 版本.
算法会修改元素的值,但是不会添加和删除元素,因为序列并不包含底层容器的信息(算法操作的是迭代器,不知道实际用的是什么容器)。如果要添加删除,得自己手动直接操作容器。
尽可能使用它们编写程序,而不是从头另起炉灶。
并行算法
有两种执行方式:
- 并行执行:任务在多线程中完成。
- 数组化执行(向量化执行):在单线程用 SIMD 完成。
<execution> 中有命名空间 execution,会有如下参数:
- seq 顺序执行
- par 如果可能,则并行执行
- unseq 非顺序(数组化) 执行 如果可能
- par_unseq 并行执行和数组化执行 如果可能
考虑根据硬件使用并行算法。
sort(par_unseq, v.begin(), v.end());建议
- 搜索的时候,通常返回输入序列的末尾位置来表示未找到。
- 使用 using 类型别名清理杂乱的符号。 当然不是让你在全局作用域用 using。
第14章 范围
range 实际上也是概念.
range 有如下定义方式:
- 一对 bgein end 迭代器
- 一对 bgein n,n是元素个数
- 一对 bgein pred,pred 是谓词,如果
pred(p)为真,则表示达到了范围末端。
视图
视图是查看范围的一种方式.
filter_view v {r, [](int x) { return x%2; }}; // 查看 r 中的奇数
for (int x : v)
cout << x << ' ';类似还有 take_view,也就是拿前几个。
可以不写名字直接玩视图嵌套。 函数式管道:初现端倪
for (int x : take_view{ filter_view {r, [](int x) { return x%2; } } , 3})
cout << x << ' ';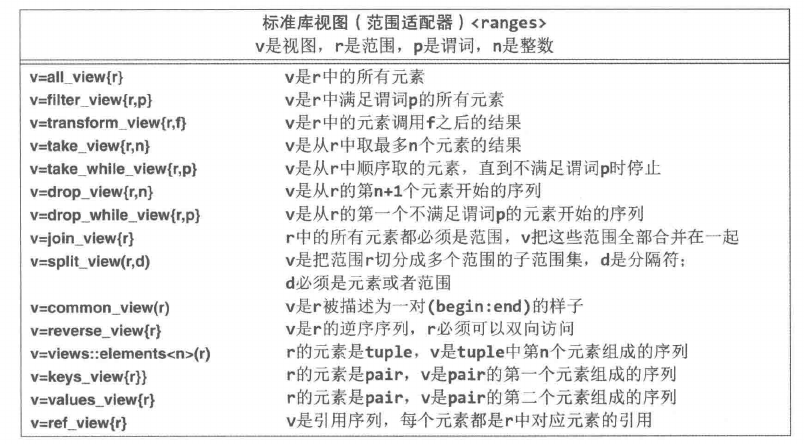
不抄了,自己看。
视图和范围很相似,但区别在于 视图不拥有元素本身,释放范围的元素责任在范围身上。所以视图的生命周期不能大于范围的生命周期。
视图复制开小很低,可以用值传递。
生成器
范围工厂.

itoa_view 就类似 python 的 range 了,可以生成数字序列。
管道
for (int x : r | views::filter(odd) | views::take(3)) // odd 是谓词
cout << x << ' ';管道从左至右执行。
这些过滤器函数定义在 ranges::views 中.
视图和管道的实现涉及一些令人毛骨悚然的模板元编程,如果你对性能表示担忧,请确保先对你实现的性能进行测量,确定其是否符合需求。如果不符合,可以用传统的替代方案来实现。
我听劝,我不看怎么实现的了。
概念概述
怎么跑这章来了.

多少有点过于魔法了,用到我再记吧.
建议
- 如果迭代器对的样子变得冗长,用范围版本算法
- 理想的类型应满足 relugar 概念。
- 尽可能使用标准库的概念。
第15章 指针
容器和指针抽象的共同点是,要想正确且高效地被使用,需要封装一组数据及函数来访问和操作它们。
标准规定封装的类需要在时间和空间效率上与内置类型的正确使用一样好。
指针类型
unique_ptr & shared_ptr

拥有所有权 的指针意味着它负责删除所指的对象.
<memory> 中,标准库提供了两个指针来帮助自由存储中的对象:
unique_ptr代表唯一所有权,它的析构函数会销毁它的对象.shared_ptr表示共享所有权,最后一个共享的析构函数负责销毁它的对象.
请确保确实需要使用共享所有权的时候才使用 shared_ptr.
直接构造对象并返回智能指针的函数 make_shared() make_unique().
能用容器还是用容器,不能再用智能指针。
我们什么时候使用“智能指针”(例如,unique_ptr)而不用资源句柄或者专门为资源设计的操作(例如vector或thread)?不出所料,答案是“当需要指针语义时”。
span
<span> 中的 span,本质上是一对 (指针, 长度) 值来表示元素序列.
span 没有所有权. 类似 string_view.
用 span 替代指针序列会好,因为包装过,可以直接用 范围 for,不用太在意范围检查.
不过 span 用下标访问的时候没有范围检查。
容器
有一些特化的容器不完全适配 STL 的框架,不过呼声很高所以在标准库里面。
array
<array> 的 array<> 是定长数组,比起 vector 可以存在栈上.
使用 array 没有任何额外开销.
此外 array 的另一个好处是比起 [] 数组可以防止隐式类型转换(因为数组和指针可以直接赋值,在 c 语言里面).
bitset
bitset<N> 提供 N bit 序列。
这个也是编译时已知的定长序列.
pair
只是因为常用,而且确实很好用.
<utility> 的 pair<T,U> 表示一对值。
pair 的成员变量命名为 first 和 second.
make_pair
tuple
tuple 异构的容器,可以装不同类型。作为零或多个元素的 pair 的泛化.
可以用索引访问.
string fish = get<0>(t1);
int count = get<1>(t1);
double price = get<2>(t1);通过索引访问tuple的成员是泛型的、不优雅的,而且容易出错。幸运的是,tuple中具有唯一类型的元素可以通过其类型被“命名”:
auto fish = get<string>(t1);
auto count = get<int>(t1);
auto price = get<double>(t1);我能不能这样?
string fish = get(t);
int count = get(t);
double price = get(t);tuple 绝大部分用途隐藏在更高级别的框架,比如说结构化绑定访问:
auto [fish, count, price] = t1;tuple 真正优势在于必须将未知数量的未知类型元素作为对象存储和运输的时候。
可变类型容器
感觉有点奇怪. 全是模板魔法.

建议
- 库不是很大很复杂才有用.
- 如果序列可以使用 constexpr 大小,选择 array.
第16章 实用工具
草略看了,用到我再回来补充。
时间
<chrono>
system_clock::now().
duration 可以用 duration_cast<>() 转换单位.
std::chrono_literals 提供了后缀.
.ok() 可以检查日期是否合理。
函数适配
mem_fn() 生成函数对象。
function 类型是标准库的一种类型,function 类型的对象是函数对象。
function 对象会产生运行时开销。
function 对象不参与重载,如果要重载,考虑 overloaded.
类型函数
类型函数是以输入参数为类型或返回值为类型的函数,在编译时求值。
<limits> numeric_limits 提供了很多信息例如。
constexpr float min = numeric_limits<float>::min(); // 最小正浮点数概念也属于类型函数。
符号约定令人困惑。标准库将
_v用于返回值的类型函数,_t用于返回类型的类型函数,这是C和C++概念诞生以前C++弱类型时代的遗留物。没有任何标准库类型函数同时返回类型和值,因此这些后缀是多余的。对于标准库和其他地方的概念,不需要使用也没有使用任何后缀。
类型函数是「编译期计算」。
类型谓词

条件属性
类定义的方法可以用 requires 来约定特定概念下的类型才能有的属性和方法。
类型生成器
许多类型函数返回类型,因为它们通常计算出新的类型。这类类型函数称为 类型生成器。
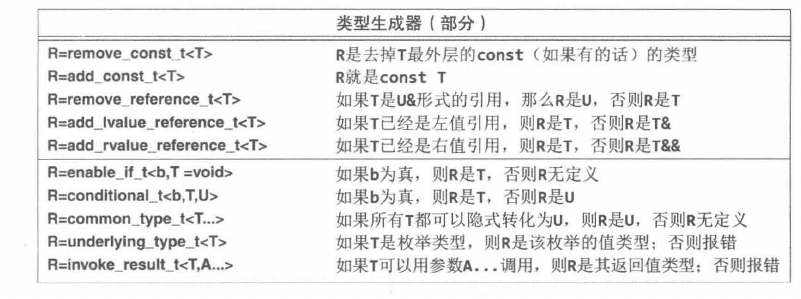
关联类型
…
source_location
在写出跟踪消息或错误消息时,我们通常希望将源代码的位置作为该消息的一部分。标准库为此提供了source_location.
const source_location = source_location::current();cpp20 前可以用 __FILE__ __LINE__ 宏来完成。
move() 和 forward()
std::move() 转换为右值引用。
不过 move 诱人且危险。对大多数场景来说很容易出错,所以除非有显著并且必要的性能改进,否则不要用 move.
转发参数可以用 forward.
位操作
<bit>
bit_cast<> 可以将一种类型的值转成另一种相同大小的类型。
退出程序
exit(x)调用atexit()注册的函数,然后用返回值x退出程序。abort()立即无条件退出程序。quick_exit(x)以at_quick_exit()注册的函数退出。terminate()调用terminate_handler. 默认的是abort().
通用库不要无条件终止。
建议
- 对库来说,大而全不如小而精。
- 在对效率下结论之前,要对程序进行计时测量。
- 用 function 存储任何被调用的东西。
第17章 数值计算
数学函数
<cmath> 有很多标准数学函数。
<complex> 有这些函数的复数版本。
<cmath> 和 <cstdlib> 有很多数学功能.
数值计算算法
<numeric> 中,可以找到一些泛型数值计算方法。
比如说 gcd 和 lcm.
当然也有并行版本。
复数
<complex> 被做成了模板,为了支持不同的标量类型.
随机数
<random>
随机数生成器有两部分组成:
- 产生随机值或者伪随机值的引擎
- 将值映射到范围内的数学分布
分布的示例有uniform_int_distribution(生成所有整数的可能性相同)、normaldistribution(“钟形曲线”的正态分布)和exponential_distribution(指数增长);每个示例都有一些指定的范围。例如:
向量算术
<valarray> 提供了类似 vector 的模板类,没 vector 通用,但是对数值计算有优化。
而且能支持常见算术运算和数学函数。
可以进行 跨步访问。
数值界限
<limits> 提供了描述内置类型的类。
类型别名
奇怪的_t后缀是C时代的遗留物,当时认为在名称上反映出它是一个类型别名很重要。
最难蚌的。
<stddef>
数学常数
数学常数一般有两种,一种是模板,一种是常用的短名称。

建议
- 用
numeric_limits可以访问数值类型的属性 - 用
numeric_limits检查数值类型是否满足特定的计算需求
第18章 并发
重量级的一章.
标准库并发特性重点提供系统级并发机制的支持,而非直接提供复杂的高层并发模型. 那些高层并发模型,可以基于标准库工具构建,并以库形式提供。
不要认为并发是灵丹妙药。如果一项任务可以按顺序完成,那么这样做通常更简单、更快捷。因为,将信息从一个线程传递到另一个线程可能会非常昂贵。
C++ 支持协程,也就是说,函数可以在调用间保持它们的状态.
任务task 和 线程thread
再次说明,cout 没有线程安全. 要么只有一个用流,要么用 osyncstream.
C++ 的线程共享单一地址空间。
定义并发程序的任务时,我们的目标是保持任务的完全隔离,唯一的例外是任务间通信的部分,而这种通信应该以简单而明显的方式进行。思考并发任务的最简单的方式是将它看作一个可以与调用者并发执行的函数。为此,我们只需传递参数、获取结果并保证两者不同时使用共享数据(没有数据竞争)。
thread 产生线程,join() 等待线程完成(合并) .
jthread 是包装后的办法,通过 RAII 来 join().
也就是说,jthread 会在要析构的时候自动合并线程.
由于共享单一地址空间,所以线程可以通过共享对象相互通信,而不用像进程那样通信麻烦。
ref() 是来自 <functional> 的类型函数,可以将变量视为引用而不是对象.
ref() 是引用包装器,能够将对象包装成引用,并且可以被拷贝和存储在容器(实际上就是包了个指针给你用)
返回结果有两种常见的,一种是直接传进去引用直接修改引用,另一种是将所有结果作为单独的参数传递。
共享数据
锁.
mutex 和锁
<mutex>
正常的 lock mutex 就不说了.
注意 RAII 的使用,也就是 scoped_lock 和 unique_lock,比显式锁定和解锁更安全.
socped_lock 可以防 多锁。
scoped_loc lck {mutex1, mutex2, mutex3};scoped_lock 只有在获取所有 mutex 参数后才会继续,而且持有 mutex 的时候不会阻塞.
通过共享数据进行通信是非常底层的操作。尤其是,程序员必须想办法了解各种任务已经完成和完成的工作。在这方面,使用共享数据不如使用函数调用和返回。另一方面,有些人笃信共享数据一定比拷贝函数参数和返回值更有效率。当涉及大量数据时确实如此,但锁定和解锁是相对昂贵的操作。而且,现代机器非常擅长拷贝数据,尤其是紧凑型数据,例如,vector元素。所以不要因为“效率”而不假思索地选择使用共享数据进行通信,最好先测量再做出选择。
共享数据的常见方式之一是多线程读取和单线程写入。shared_mutex 支持这种「读写锁」的用法。
shared_mutex mx;
void reader() {
shared_lock lck {mx};
// 读
}
void writer() {
unique_lock lck {mx};
// 写
}原子量
mutex涉及操作系统,算是代价较重的机制。它允许在没有数据竞争的情况下完成任意数量的工作。然而,有一种更简单、更便宜的机制来完成少量工作:atomic变量。
省流就是保证单个变量读写是不可分割的,多线程写也不会发生数据竞争。依赖于底层的原子指令.
简单的使用示例是一种双重检查锁变体。
mutex mut;
atomic<bool> init_x;
X x;
if (!init_x) {
lock_guard lck {mut};
if (!init_x) {
init_x = true;
}
}我记得好像以前冲浪看过这种原子量以及双重检查锁的使用方式,但是我忘了。如果不是性能,应该不会选这种。
等待事件
<condition_value> 提供的 condition_value 提供了一种机制,允许一个 thread 等待另一个 thread。
condition_value.wait() 和 condition_value.notify_one() 、condition_value.notify_all().
如果是一次性的等待,我觉得选 promise/future 会更好.
小知识:condition_value 能防 忙等待 busy waiting,也就是说循环反复检测是否达成条件不如用 condition_value 等对面通知。
使用的时候要注意防止 虚假唤醒。(我感觉多线程要单开笔记写写了),也就是被唤醒的时候用闭包检查一下是否真的满足条件了。
void Consumer() {
while (true) {
unique_lock lck {mmutex};
mcond.wait(lck, [] { return !mqueue.empty(); });
auto m = mqueue.front();
mqueue.pop();
lck.unlock();
// do something with m...
}
}wait 大概操作就是,放下锁,然后等时机,再拿起锁。
任务间通信
更高层的通信。
标准库提供了一些特性,允许程序员在抽象的任务层(工作并发执行)进行操作,而不是在底层的线程和锁的层次直接进行操作。
Future / Promise
promise的主要目的是提供与future的get(相匹配的简单的“放置”操作(名为set_value()和set_exception())。“期货”(future)和“承诺”(promise)这两个命名是有历史原因的,不必责备或者赞颂我,现实中像这样的双关语有很多。
好冷的双关……
我查了一些关于 future/promise 常用的 api.
promise:
- promise(promise&& x)
- get_future()
- set_value()
- set_exception()
future:
- get
- wait
- wait_for
- wait_until
- share
packaged_task
还有高手.
概略讲就是把任务打包成 packaged_task<> 类型,并且可以用 get_future() 获取 future./
#include <future>
#include <numeric>
#include <vector>
using namespace std;
double accum(vector<double>::iterator beg, vector<double>::iterator end, double init) {
return accumulate(&*beg, &*end, init);
}
double comp2(vector<double> &v) {
packaged_task pt0{accum};
packaged_task pt1{accum};
future<double> f0{pt0.get_future()};
future<double> f1{pt1.get_future()};
double *first = &v[0];
thread t1{move(pt0), first, first + v.size() / 2, 0};
thread t2{move(pt1), first + v.size() / 2, first + v.size(), 0};
return f0.get() + f1.get();
}async
还有高手,超级轮椅.
本章所追求的思路是我认为最简单但最强大的思路:将任务视为可能碰巧与其他任务同时运行的函数。它不是C++标准库唯一支持的模型,但可以很好地满足广泛的需求。可以根据需要使用更微妙和棘手的模型(例如,依赖共享内存的编程风格)。
async 自己会决定使用多少线程多少资源,所以用户只要管设计和判断任务是否需要并发进行就可以了。
反过来,如果需要用到共享资源,引入锁机制,用 async 就不太合适了,因为 async 都不知道自己开了多少个线程运行任务。
stop_source && stop_token
直接杀死线程太残暴,也会错过很多东西。
可以用 stop_token 来作为其他线程请求停止当前线程的信号量。
将 stop_token 作为量传入。
stop_token 不会引发竞态问题。
可以用 stop_token.stop_requrested() 测试是否有其他线程请求中止此线程。
stop_source 产生 stop_token。
使用 stop_source.request_stop() 发起停止请求。
感觉多线程通信基本就是这种一对头尾分到不同的线程上,用来通信。
协程
协程是一种在调用之间保持其状态的函数。在这方面,它有点像函数对象,但在调用之间,协程可隐式地、完整地保存与恢复其状态。请看下列经典例子:
generator<long long> fib() {
long long a = 0;
long long b = 1;
while (a < b) {
auto next = a+b;
co_yield next;
a = b;
b = next;
}
co_return 0;
}协程调用的状态存储到了 generator<> 处。
保存和恢复状态变得乏味、难以优化且容易出错。实际上,协程是在调用之间保存堆栈帧的函数。co_yield返回值并等待下一次调用。co_return返回值并终止协程。
协程可以是同步的(调用者等待结果),也可以是异步的(调用者做一些其他的工作直到它从协程中查找结果)。
底下叽里咕噜讲了一大堆协程如何在 协作式多任务 中发挥重大作用,但是我只感觉干巴巴。
建议
- 用并发提高响应速度或吞吐率。
- 将进程作为线程的替代方案。
- 内存模型的存在是为了大多数程序员不必考虑计算机的机器架构级别。
- 内存模型使内存大致按照程序员期望的那样呈现。
- 原子操作允许程序员进行无锁编程。
- 无锁编程还是留给专家吧。 这两条建议没蚌住。
- 有时串行比并发解决方案更快也更简单。
- 优先选择并发算法而不是直接用并发。
- 尽量用 RAII 自动管理锁,而不是显示锁定解锁。
- condition_value 中使用 unique_lock 而不是 scoped_lock.
- 追求简洁。
- 从并发任务角度考虑,而不是直接从 thread 角度考虑。
- 用
async()来启动简单任务。
第19章 历史和兼容性
奖励关。
我很想把整章都 copy 下来,这可能是整本书最没那么烧脑的地方。
C++ 历史
C++ 11 标准制定工作的总体目标是:
- 使 C++ 成为系统程序设计和库构造更好的语言。
- 使 C++ 更容易教和学。
cpp11 开始了三年更新一次标准的策略。cpp14 是完善 cpp11 的小更新,而 cpp17 本来应该是大版本,结果很多东西不是没准备好就是陷入争议和缺乏设计方向,变成了中等版本的更新。在 cpp20,终于提供了承诺已久但是急需的重大功能更新(模块、概念、协程、范围还有很多小功能)。
C++ 模型:
- 静态类型系统,对内置类型和用户定义类型具有同等支持。
- 值语义和引用语义。
- 系统和通用资源管理(RAII)
- 支持高效的面向对象编程
- 支持灵活高效的泛型编程
- 支持编译时编程
- 直接使用机器和操作系统资源
- 通过库提供并发支持
C++ 特性演化
我真的很想把这个全部copy出来。
cpp11
查看语言特性列表很容易让人感到困惑。需要记住,语言特性不是单独使用的。特别是,大多数C++11新特性如果离开了旧特性提供的框架将毫无意义。

{}统一初始化- 初始化类型推导
auto - 避免类型窄化
constexpr- 范围 for
nullptrenum classstatic_assert{}到std::initializer_list的映射- 右值引用,移动语义
- 匿名函数
- 可变参数模板
- 类型和模板别名
- Unicode 字符
long long整数类型alignas和alignof对齐控制- 在声明中将表达式的返回类型作为类型
decltype - 原始字符串字面量
- 后置返回类型语法
- 属性语法和标准属性
[[carries_dependency]][[noreturn]] noexceptinline 命名空间__func__宏返回当前函数名称和字符串- 委托构造函数
- 类内成员初始值设定项
defaultdelete控制对象成员默认实现- 用户定义字面量
- 显示类型转换符
extern template- 函数模板默认模板参数
- 继承构造函数
overridefinal- SFINAE
- 内存模型
thread_local线程本地存储 etc
cpp14

cpp17

cpp20

cpp11 stl

cpp14 stl

cpp17 stl

cpp20 stl

移除的特性
可以去搜,一个比一个难蚌。
py3: 我干掉了 100 万 py2 代码.
连 C++ 这种看重历史兼容的语言都要砍的特性,可以说一想到历史上有很多人踩过坑,大佬们讨论是否要为了兼容性去砍掉就想笑。
注意的是 export 在 cpp98 后被砍掉了,转而现在的 export 实际上是 cpp20 添加的 模块化 语法的关键字。 难怪我看以前老教程 cpp 里面用 export 导出,现代 cpp 又用这个来导出模块,我还以为是一个关键字能两用,没想到是砍了。
C / C++ 兼容
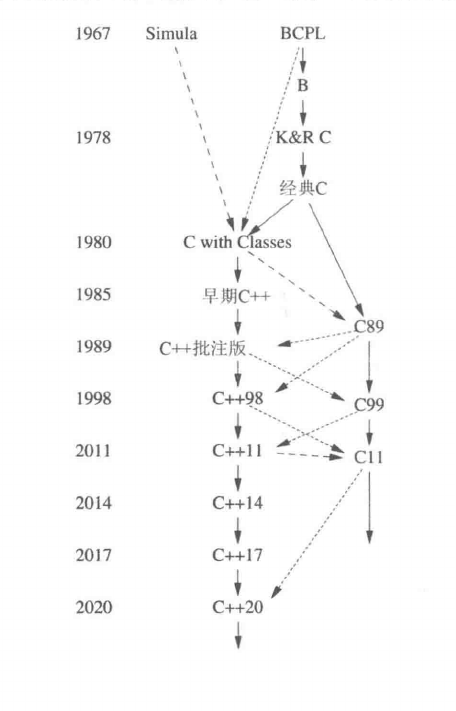
经典家谱图,太好笑了。
还有导演剪辑版。
书评
其实我懒得写书评的,但是这本书确实值得写。既是为了作推荐,也是为了回顾全书,并表达不说出来就会难受的感慨。
这本书是 C++ 之父写的,正如其名,这本书会带着读者度过一段轻松愉快的现代 C++ 之旅,给(有经验的)读者展示了现代 C++ 的做法和特点。开篇有很长很长的推荐序,我就知道这本书可能不简单,而实际读完之后感觉确实很不错。很适合有其他语言经验的、赶时间的、或许写过远古 C++ 的读者看。
C++ 作为有着悠久历史的语言,也是和 C 语言一样广为人知的语言。常常被以刻板印象所影响,为人们所诟病石山。在开始读这本书前,我也同样认为这是一坨带有丰厚历史的石山,并期待这本书能带来改变。
前面八章讲了 C++ 的核心语法,而从第九章开始到第十八章则介绍了 C++ 的标准库,最后以第十九章 C++ 历史为主题进行了概览。
而实际读完了,发现确实是石山,但是一切的石都很有道理,并且其实石山来自于使用者自己而非语言。C++ 实际上是一门考虑历史兼容性但同时又与时俱进海纳百川的语言,既可以贴近底层的写,也可以贴近上层的写。因为 C++ 海纳百川带来了很多特性,而不会限制使用者怎么写,因而使用 C++ 可以带来自由的好处,也会带来自由的坏处,也就是上下限差距巨大的代码。典型的莫过于很多地方用到的各种奇特 C++ 变体。
作者从高屋建瓴的视角下的编程,尤其是每章末尾的建议环节,给人印象深刻。在谈及约束、泛型、多态话题上,给了很多更接近本质(即「指挥计算机解决问题」)的视角。举例说,在设计一个类、函数时谨慎思考,考虑其约束和作用,亦或是在使用特性时,考虑特性是否合适当前场景,特性能带来什么好坏,而不是有什么用什么。这是此前我在其他教程中没有了解过的(通常只是考虑如何用仅有的特性实现,而非选择何种特性实现并优化)。虽然显然没能吸收完全,但是总感觉能看懂一些神仙为什么而争吵。
看得让人有点爱上 C++ 了。如果说其他语言是在加规则让人更好的写出好程序,而 C++ 选择放任自由,让使用者决定怎么写好程序。这种自由如同大型开放世界冒险游戏一样有趣(但烧脑)。
总而言之,电波系好书。